TM1 Turbo Integrator is quite limited when it comes to loading data from different sources and transforming and cleaning the data before it can be loaded to cubes. Therefore you might have a dedicated data repository for your TM1 solution for example a data warehouse. Sometimes you need to refresh the DW data before it can be loaded to your TM1 solution. Then you face the question: how to manually execute data warehouse refresh ETL jobs? Of course you can always use SQL Server Management Studio and run the jobs there but if there is a need for the end users to manually refresh the data during working hours it would be nice to provide them a single-platform solution do accomplish this.
So lets face it: maybe you already have some user interface for the end-users to execute some TM1 solution’s internal TI-processes. It could be via TM1 Perspectives web sheets on TM1Web, straight from TM1 Architect etc. Wouldn’t it be nice to have the ability to run external DW loading processes from the same place? Here is how to accomplish it.
Set up the logins and jobs in SQL Server

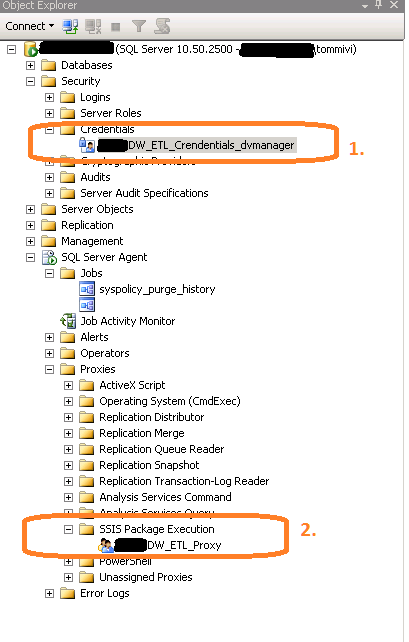
First of all you need to ensure that the user account that will be used when from TI process connects SQL Server has all the needed permissions in the SQL Server instance. At least the three following things must be ensured:
- Login has SQLAgentUserRole checked in the msdb database. Then the login will have permissions on only local jobs and job schedules that it owns
- Login has the required permissions to access the source files etc. That can be solved by defining a proxy account and I have described it in my previous blog post.
- The job must be owned by the same user you will use when connecting from TM1. This is because we don’t want to throw admin permissions around and we want the user to have only rights to one or couple of jobs not all of them
Set up TI process to run the job: zSQLJob_StartJob
To accomplish we need two different TI processes: one to actually execute the job and one to determine whether the job execution has ended or not. Let’s start with the main process zSQLJob_StartJob. It has one parameter p_sql_job_name which will contain the name of the job that will be executed. The process itself is quite straightforward and here is the complete code:

What it does is basically just opens the ODBC connection to the msdb database of the SQL Server instance and then executes the job. The magic here is that the process won’t finish until the job on SQL Server has finished. To have this functionality we need to poll the msdb database every 5 seconds and find out if the job has finished or not.
Set up TI process to determine the status of the running job: zSQLJob_CheckJobStatus
To find out whether the job has finished or not we just query the job status directly from the msdb database. To do that we use the following SQL query and put it in the “Data Source” tab like this:
SELECT CASE
WHEN EXISTS (
select job.Name, job.job_ID, job.Originating_Server,
activity.run_requested_Date, datediff(minute, activity.run_requested_Date, getdate()) as Elapsed
from msdb.dbo.sysjobs_view job
inner join msdb.dbo.sysjobactivity activity
on (job.job_id = activity.job_id)
where run_Requested_date is not null and stop_execution_date is null
and job.name = 'JOHIDW_Update_Publishing' ) THEN 1 ELSE 0 END AS JOB_RUNNING_STATE

The only magic with this process is to save the single result value to the global variable vnJOBSTATE_global that we defined in the previous master process. If the value is 1 it means that the job is still running and the master process keeps polling the msdb database every 5 seconds. When the job finishes the value turns to 0 and the master process can finish as well.
Conclusion
There may be times when you need to execute SQL Server jobs to make sure your data to be loaded to TM1 is up-to-date. With this example you can do a nice and easy integration between TM1 and SQL Server and allow end-users to execute simple SQL Server jobs if needed.